Object Detection
1. Overview
YOLO11 is Ultralytics' next-gen object detection model with exceptional speed and accuracy. Local deployment on NVIDIA Jetson devices (Orin Nano/NX/AGX) enables efficient, low-latency AI inference.

Guide covers:
- Environment setup and JetPack installation
- Quick YOLO11 run via Docker
- Local YOLO11 installation
- TensorRT acceleration
- DLA acceleration and benchmarks
YOLO11 runs with ultra performance on Jetson Orin Nano, ideal for edge AI.
2. Environment Setup
Hardware Support
| Device | JetPack Version | AI Performance |
|---|---|---|
| Jetson Nano | JetPack 4.6.x | 472 GFLOPS |
| Jetson Xavier NX | JetPack 5.1.x | 21 TOPS |
| Jetson Orin NX 16GB | JetPack 6.x | 100 TOPS |
| Jetson Orin Nano Super | JetPack 6.x | 67 TOPS |
Recommended JetPack ≥5.1, enable max performance:
sudo nvpmodel -m 0
sudo jetson_clocks
3. Quick Start with Docker (Recommended)
Fastest method: Use pre-built Ultralytics image.
sudo docker pull ultralytics/ultralytics:latest-jetson-jetpack6
sudo docker run -it --ipc=host --runtime=nvidia ultralytics/ultralytics:latest-jetson-jetpack6
Includes YOLO11, PyTorch, Torchvision, TensorRT.
4. Local Installation (Optional)
For custom environments.
Step 1: Python Environment
sudo apt update
sudo apt install python3-pip -y
pip install -U pip
Step 2: Install YOLO11
pip install ultralytics[export]
Step 3: Install PyTorch and Torchvision
For JetPack 6.1 + Python 3.10:
pip install https://github.com/ultralytics/assets/releases/download/v0.0.0/torch-2.5.0a0+872d972e41.nv24.08-cp310-cp310-linux_aarch64.whl
pip install https://github.com/ultralytics/assets/releases/download/v0.0.0/torchvision-0.20.0a0+afc54f7-cp310-cp310-linux_aarch64.whl
Install cuSPARSELt for torch 2.5.0:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/arm64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
sudo apt-get -y install libcusparselt0 libcusparselt-dev
Verify torch and GPU:
python3 -c "import torch; print(torch.__version__)" # 2.5.0a0+872d972e41.nv24.08
python3 -c "import torch; print(torch.cuda.is_available())" # True
Step 4: Install onnxruntime-gpu
pip install https://github.com/ultralytics/assets/releases/download/v0.0.0/onnxruntime_gpu-1.20.0-cp310-cp310-linux_aarch64.whl
5. TensorRT Acceleration
Ultralytics supports exporting models to TensorRT (.engine) for performance boost.
Python Example
from ultralytics import YOLO
model = YOLO("yolo11n.pt")
model.export(format="engine") # Generates yolo11n.engine
trt_model = YOLO("yolo11n.engine")
results = trt_model("https://ultralytics.com/images/bus.jpg")
CLI Example
# Export to TensorRT
yolo export model=yolo11n.pt format=engine
# Run inference
yolo predict model=yolo11n.engine source='https://ultralytics.com/images/bus.jpg'
6. DLA (Deep Learning Accelerator)
Jetson devices feature DLA for lower power and higher concurrency.
Python Example
model.export(format="engine", device="dla:0", half=True)
CLI Example
# Export with DLA
yolo export model=yolo11n.pt format=engine device="dla:0" half=True
# Run on DLA
yolo predict model=yolo11n.engine source='https://ultralytics.com/images/bus.jpg'
Some layers may fall back to GPU if unsupported by DLA.
7. Object Detection Example
import cv2
import time
from ultralytics import YOLO
# Load TensorRT model
model = YOLO("yolo11n.engine")
# Open USB camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
# FPS calculation
fps = 0.0
frame_count = 0
start_time = time.time()
print("📸 Real-time detection started. Press 'q' to quit.")
while True:
ret, frame = cap.read()
if not ret:
break
t0 = time.time()
results = model(frame)
annotated = results[0].plot()
frame_count += 1
t1 = time.time()
fps = 1. / (t1 - t0)
cv2.putText(annotated, f"FPS: {fps:.2f}", (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.imshow("YOLO11 - TensorRT Real-time Detection", annotated)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
cap.release()
cv2.destroyAllWindows()
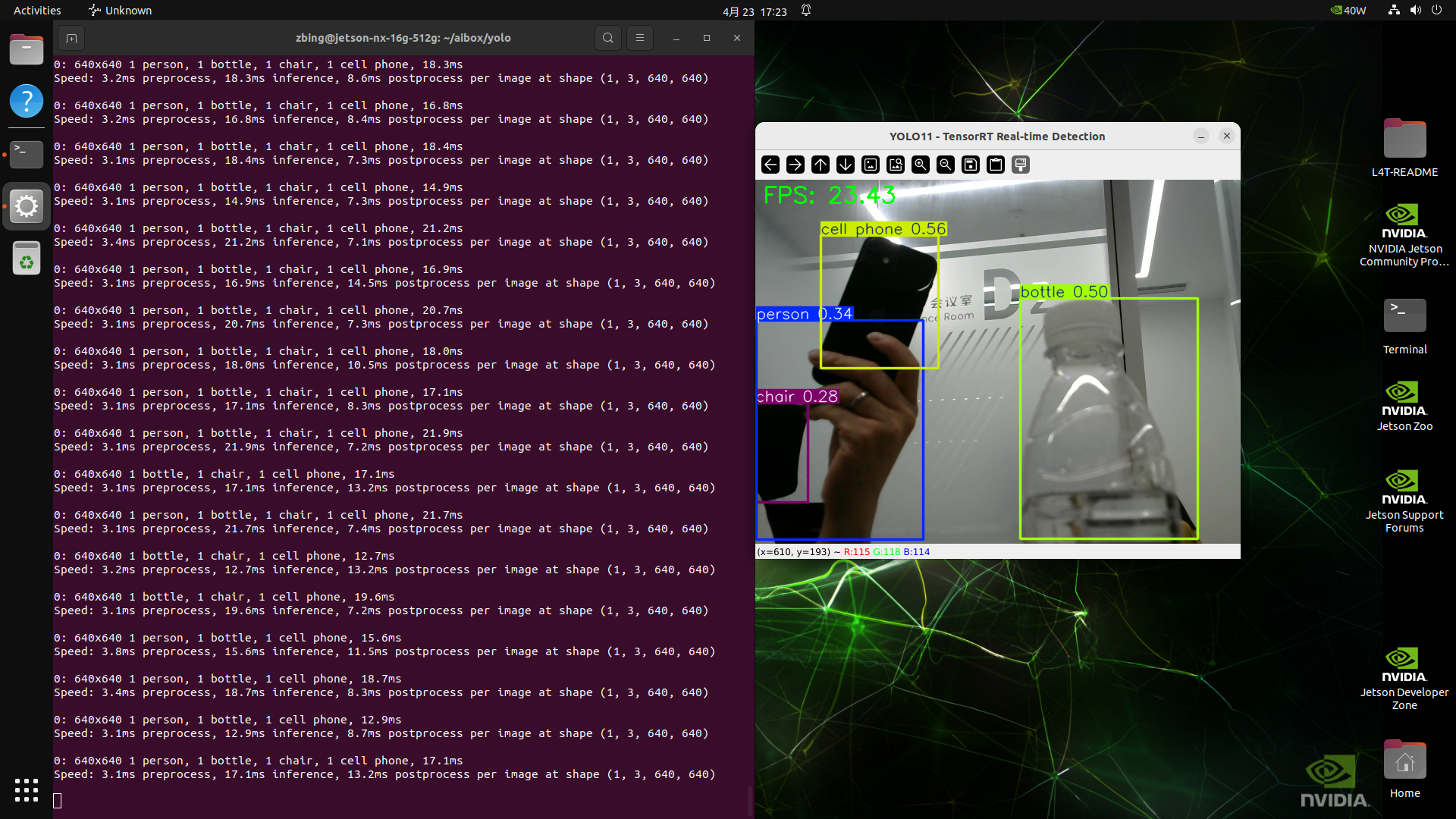
7. Benchmark Comparison
| Model Format | Orin Nano (ms) | mAP50-95 | Orin NX (ms) |
|---|---|---|---|
| PyTorch | 21.3 | 0.6176 | 19.5 |
| TorchScript | 13.4 | 0.6100 | 13.03 |
| TensorRT (FP16) | 4.91 | 0.6096 | 4.85 |
| TensorRT (INT8) | 3.91 | 0.3180 | 4.37 |
💡 TensorRT INT8 fastest, FP16 better accuracy.
8. Performance Tuning
| Optimization | Recommendation |
|---|---|
| Power Mode | sudo nvpmodel -m 0 |
| CPU/GPU Freq | sudo jetson_clocks |
| Monitoring | sudo pip install jetson-stats → jtop |
| Memory | Proper swap allocation |
9. Common Issues
| Issue | Solution |
|---|---|
| Can't import PyTorch | Use correct Jetson .whl |
| TensorRT slower than expected | Enable jetson_clocks + FP16 |
| Can't pull Docker image | Ensure --runtime=nvidia |
| No tensorrt in venv | Copy from host: cp -r /usr/lib/python3.10/dist-packages/tensorrt your_venv/lib/python3.10/site-packages/ |